Code Book, part 1b (Further back-end concepts)
Written by Chris Graham (ocProducts)
« Return to Code Book table of contentsTable of contents
-
Code Book, part 1b (Further back-end concepts)
-
Back-end (continued)
- Do-next-manager interfaces
- The translation table
- The persistent cache
- Core APIs
- Results tables
- URLs
- Breadcrumbs
- Redirects
- Database structure
- Diff tools
- Member profile customisation
- Running extra startup code
- Adding to the Admin Zone/CMS menus
- Adding a new symbol, to refer to custom data and functions within templates
- Running scheduled scripts
- Running temporary code
- How Tempcode works
- Development mode
- Custom version of PHP
- Importers
- eCommerce
- Forum drivers
- Permissions
- SEO metadata
- Feedback mechanisms
- CRUD modules
- Attachment-supporting fields: Language lookup, Comcode, and attachments
- Non-bundled addons
-
Back-end (continued)
Back-end (continued)
Do-next-manager interfaces
A 'do-next-manager' is a special navigation interface in Composr that is used in two roles:- What the user wants to do next. These are often shown after an administrative/content-management action is performed.
- Where to go. These are used for browsing through the Admin and CMS zone interfaces.
The do-next-manager provides a full-screen choice of options, laying out those options with icons.
The do-next-browser is called up by passing in an array of lines. Here is an example of a simplified call to one (the do_lang lookups have been removed – this is hard-coded as English for simplicity):
Going from top to bottom:
- the icon theme image name
- the page name (cms_news)
- the list of URL parameters (in this case, one: type as add)
- the zone (cms)
- the link caption
- the hover text
To place a new item into the Admin Zone or CMS "Where to go" menus, create a new hook file in sources/hooks/systems/page_groupings. The syntax is essentially as above, and there are plenty of existing files to use as examples.
The translation table
If multi-language content is enabled, all text strings in Composr databases (including forum posts, page comments, and generally any user-submittable text) are stored in the translate table. There are two reasons for this:- It can be used to store parsed Comcode as Tempcode format, effectively a cache
- Composr's API supports multi-language websites in the truest sense. Meaning that potentially, translated versions of virtually any content can be supplied for visitors. As of version 4.2 this is fully supported.
All translatable attributes in Composr are given priorities. The priority numbers are defined as follows…
- absolutely crucial and permanent/featured
- pretty noticeable: titles, descriptions of very-important
- full body descriptions
- for individual members, or very low level
The persistent cache

The persistent cache is implemented in 3 ways, and one of them is used, or none if it is not enabled (by default it isn't):
- via the eAccelerator/mmcache/APC/xcache/wincache PHP extensions (requires PHP extension)
- via the memcached server daemon (requires either memcache or memcached PHP extension to access it)
- via file writing
The usage of the cache is very simple. You can:
- read a named (nameable by any data structure, like an array) entry (persistent_cache_get)
- write one named entry (persistent_cache_set)
- delete one named entry (persistent_cache_delete)
- delete them all (persistent_cache_empty)
There is a 'server' level cache, and a 'site' level cache. The programmer only needs to distinguish these on writes. The server level allows storage for access by all Composr installations of the same version (more efficient due to memory sharing). It is very rare that a server level cache may actually be done, due to the high configurability of individual sites.
Tips/guidelines for usage

- delete the entry on writes that affect it, and attempt to load the entry on reads, and put it when it was not in the cache on a read and we had to do a full calculation; do not bother caching when new data is written, as its code that will give a tiny performance increase due to the relatively rare situation
- use the server-level cache when appropriate (when things are known to be relevant to all installs and when there is no site-specific aspects to the data) and never when not
- put (where possible) user-specific stuff in templates as symbols rather than parameters, so that they may be cached so as not to depend on users (symbols 'survive' the cache and get reinterpreted after cache extraction). If you can't do this, and the data does contain user-specific data, you'll need to cache against each user, and that is very inefficient
- make use of cache layers: e.g. we didn't optimise some functions in Composr because higher level block caching would often make my optimisation almost pointless
- cache what is used most: we want to support lots of users, so we need regular website access use cases to be most efficient – making admin actions more efficient is almost pointless

- forget to to cache against theme where appropriate (i.e. do not assume all users will use the same theme by caching theme-tainted data without using the theme name as part of the cache identifier)
- cache non-featured stuff that could stay in the cache forever but relatively rarely get used (even if a gallery is viewed on every page view, this is not justification to cache 100s of them: but we could cache the current IOTD block): memory is finite, do not waste it
- assume the persistent cache exists (due to its non-reliability for long term storage): if something is really important to be cached, Composr should have a dependable cache to do it

- where appropriate store false rather than null, to distinguish between 'non presence in cache' and 'not setness': often a little extra logic is needed, as Composr uses null for most "not setness" API results
- emptying the cache on admin actions is fine because they are relatively rare, compared to total hits a site gets; while it is preferable to be able to delete specific objects, that's not always possible (e.g. with Comcode pages, they are cached against theme, but having a load of loop code to selectively choose what to decache would be excessive)
- that it is not just one site per server, usually – we want to increase the number of users the server can take on average, not individual sites: memory is finite
- you must assume the cache might never remember a thing even if it is on – things get chucked out to make space, don't assume anything
- that it is okay if things keep getting lost from the cache – if something is remade every 5 minutes (the default TTL), then that means it persists for potentially hundreds/thousands of requests: a regeneration rate of 0.3% is hardly bad is it? Of course, if we are on a server with many sites, so things get regenerated after hardly being used, this is non-optimal: but we would not have had the memory to store it all anyway!
Core APIs
All the Composr APIs are documented online and visible via the PHP-doc comments. If you need to look up the purpose/usage of a function the easiest way is to do a file search from your code editor for "function <function-name>", so you can jump to the PHP-doc comment for it.Note that as a general rule, you shouldn't be using any function/method that begins _. This indicates a private/helper function.
The following are the core Composr APIs (green is used to indicate the most important APIs)…
Composr API summary (Conventional columned table)
| API | File(s) | Typical usage |
|---|---|---|
| GLOBAL |
sources/global.php sources/global2.php sources/global3.php |
Pre-loaded and available in global scope |
| Web page display | sources/site.php | Pre-loaded and available in global scope |
| Forum, members, and usergroups (forum driver layer) |
sources/forum/*.php sources/forum_stub.php sources/users.php |
Use via the $GLOBALS['FORUM_DRIVER'] object. |
| Forum, members, and usergroups (Conversr) | sources/cns_*.php | Needs require_code. Only use these functions if you can assume Conversr is running. |
| Database |
sources/database.php sources/database/*.php |
Use via the $GLOBALS['SITE_DB'] or $GLOBALS['FORUM_DB'] objects / global functions. |
| Caches |
sources/caches.php sources/caches2.php sources/caches3.php |
Use the functions, which tie into pre-instantiated cache objects (you don't need to instantiate anything). |
| CAPTCHA | sources/captcha.php | Needs require_code. |
| Comcode |
sources/comcode.php sources/comcode_compiler.php |
Needs require_code if you need anything in comcode_compiler.php. |
| Configuration | sources/config.php | Pre-loaded and available in global scope |
| Encryption | sources/encryption.php | Needs require_code. |
| Feedback (ratings, comments, etc) | sources/feedback.php | Needs require_code. |
| Files |
sources/files.php sources/files2.php |
Needs require_code if you need anything in files2.php. |
| Forms (for full tabular form interfaces, not for any time you need a standalone input field) | sources/form_templates.php | Needs require_code. |
| E-mail and SMS | sources/mail.php | Needs require_code. |
| Image manipulation | sources/images.php | Needs require_code. |
| Language and internationalisation |
sources/lang.php sources/lang2.php |
Needs require_code if you need anything in lang2.php. |
| Filtering syntax (Selectcode) | sources/selectcode.php | Needs require_code. |
| Permissions |
sources/permissions.php sources/permissions2.php |
Needs require_code if you need anything in permissions2.php. |
| Content submission security | sources/submit.php | Needs require_code. |
| Archiving and compression |
sources/tar.php sources/zip.php sources/m_zip.php (use the PHP API, this implements that if the PHP ZIP extension is not available) |
Needs require_code. |
| Templating (Tempcode engine) | sources/tempcode.php | Pre-loaded and available in global scope |
| Templating (template wrapper functions) | sources/templates.php | Pre-loaded and available in global scope |
| Templating (sophisticated interfaces) |
sources/templates_confirm_screen.php sources/templates_donext.php sources/templates_interfaces.php sources/templates_internalise_screen.php sources/templates_redirect_screen.php sources/templates_result_launcher.php sources/templates_results_browser.php sources/templates_results_table.php sources/templates_table_table.php sources/templates_view_space.php |
Needs require_code. |
| Date and time | sources/temporal.php | Pre-loaded and available in global scope |
| Overridable text files | sources/textfiles.php | Needs require_code. |
| Themes (esp theme image management) |
sources/themes.php sources/themes2.php |
Needs require_code if you need anything in themes2.php. |
| Data sanitisation | sources/type_sanitisation.php | Needs require_code. |
| File uploads | sources/uploads.php | Needs require_code. |
| Web services | sources/xmlrpc.php | Needs require_code. |
| XHTML manipulation | sources/xhtml.php | Needs require_code. |
| URL generation | sources/urls.php | Pre-loaded and available in global scope |
| Block, page, and zone querying and maintenance |
sources/zones.php sources/zones2.php sources/zones3.php (see zones.php API doc – has since been split) |
Needs require_code if you need anything in zones2.php or zones3.php. |
| Create/edit/delete forms | sources/crud_module.php | Needs require_code. |
Note that this is used to provide a base class. Many Composr modules use it, but as a base class you should never need to override this file (because you can just override or add methods when you inherit from it).
Generally any code in a file suffixed _action.php, and often code in a file suffixed _2.php (or _3.php) is involved in writing data. This is not a strictly enforced rule, and the main reason for the division is performance – it takes more CPU, disk activity, and memory, if unnecessary functions are loaded up. As writes are less common, the extra functions are usually put into a separate file. Some of the '_2.php' files never need to be loaded up manually using require_code because they are auto-loaded by stub functions in the primary files (this is a memory optimisation for the case where a set of functions are needed a lot but not always).
For AJAX handler scripts, less may be loaded into the global scope than indicated in the table, and less may generally be initialised – for performance reasons.
Results tables
If you are coding up a screen to display multiple database results you may want to use results tables.You could simply create your own table within a template, which would not be hard. However, using results tables you may be able to avoid creating a template at all, plus you get free sorting and pagination support.
Use cases:
- an index screen
- if you just have a few fields so want to show all entries at once
First call up the code:
Code (PHP)
require_code('templates_results_table');
Then you'll do a query, probably using something like:
Code (PHP)
These are the three main functions for the UI:
- results_field_title (defines field header templating)
- results_entry (defines individual result row templating)
- results_table (defines the surrounding interface)
You compose some results_field_title call results together using PHP arrays, to form the combined header.
You compose some results_entry call results together using Tempcode attach, to put the rows together.
Then you pass it, and some other stuff, to results_table.
You will also need to implement pagination and sorting. That is simply done within your initial database query. results_table will automatically bind UI widgets to the GET parameters needed to determine sorting and the start position in the result set, and the maximum number of results to return.
Finally, you can use the RESULTS_TABLE_SCREEN.tpl template to put your result into a screen, avoiding the need to even create a screen template (in most cases – you may want to add other things into the page).
A complete example (assumes a table named example, with fields name and add_date):
Code (PHP)
// We're using this API
require_code('templates_results_table');
// Read in current sorting, and apply security
$current_ordering = get_param_string('sort', 'name ASC');
if (strpos($current_ordering, ' ') === false) {
warn_exit(do_lang_tempcode('INTERNAL_ERROR'));
}
list($sortable, $sort_order) = explode(' ', $current_ordering, 2); // Invalid parameter
$sortables = array(
'name' => do_lang_tempcode('CODENAME'),
'add_date' => do_lang_tempcode('ADDED'),
);
if (((strtoupper($sort_order) != 'ASC') && (strtoupper($sort_order) != 'DESC')) || (!array_key_exists($sortable, $sortables))) {
log_hack_attack_and_exit('ORDERBY_HACK');
}
// Render header (with support for sorting within the header)
$hr = array(
do_lang_tempcode('CODENAME'),
do_lang_tempcode('ADDED'),
);
$header_row = results_field_title($hr, $sortables, 'sort', $sortable . ' ' . $sort_order);
// Query, with pagination
$max_rows = $GLOBALS['SITE_DB']->query_select_value('example', 'COUNT(*)');
if ($max_rows == 0) {
inform_exit(do_lang_tempcode('NO_ENTRIES'));
}
$max = get_param_integer('example_max', 20);
$start = get_param_integer('example_start', 0);
$rows = $GLOBALS['SITE_DB']->query_select('example', array('name', 'add_date'), null, 'ORDER BY ' . $current_ordering, $max, $start);
// Render table rows
foreach ($rows as $row) {
$fr = array(
$row['name'],
get_timezoned_date($row['add_date']),
);
$fields->attach(results_entry($fr), true);
}
// Render table
$table = results_table('Example', $start, 'example_start', $max, 'example_max', $max_rows, $header_row, $fields, $sortables, $sortable, $sort_order);
// Render screen
return do_template('RESULTS_TABLE_SCREEN', array(
'TITLE' => $title,
'TEXT' => '',
'RESULTS_TABLE' => $table;
));
require_code('templates_results_table');
// Read in current sorting, and apply security
$current_ordering = get_param_string('sort', 'name ASC');
if (strpos($current_ordering, ' ') === false) {
warn_exit(do_lang_tempcode('INTERNAL_ERROR'));
}
list($sortable, $sort_order) = explode(' ', $current_ordering, 2); // Invalid parameter
$sortables = array(
'name' => do_lang_tempcode('CODENAME'),
'add_date' => do_lang_tempcode('ADDED'),
);
if (((strtoupper($sort_order) != 'ASC') && (strtoupper($sort_order) != 'DESC')) || (!array_key_exists($sortable, $sortables))) {
log_hack_attack_and_exit('ORDERBY_HACK');
}
// Render header (with support for sorting within the header)
$hr = array(
do_lang_tempcode('CODENAME'),
do_lang_tempcode('ADDED'),
);
$header_row = results_field_title($hr, $sortables, 'sort', $sortable . ' ' . $sort_order);
// Query, with pagination
$max_rows = $GLOBALS['SITE_DB']->query_select_value('example', 'COUNT(*)');
if ($max_rows == 0) {
inform_exit(do_lang_tempcode('NO_ENTRIES'));
}
$max = get_param_integer('example_max', 20);
$start = get_param_integer('example_start', 0);
$rows = $GLOBALS['SITE_DB']->query_select('example', array('name', 'add_date'), null, 'ORDER BY ' . $current_ordering, $max, $start);
// Render table rows
foreach ($rows as $row) {
$fr = array(
$row['name'],
get_timezoned_date($row['add_date']),
);
$fields->attach(results_entry($fr), true);
}
// Render table
$table = results_table('Example', $start, 'example_start', $max, 'example_max', $max_rows, $header_row, $fields, $sortables, $sortable, $sort_order);
// Render screen
return do_template('RESULTS_TABLE_SCREEN', array(
'TITLE' => $title,
'TEXT' => '',
'RESULTS_TABLE' => $table;
));
URLs
Generating URLs
In Composr we usually avoid ever hard-coding URLs to things. There are a number of reasons for this:- We may have different URL Schemes that link to pages in very different ways
- We don't want to hard-code any assumptions about relative paths, as we may change URL/directory structure later and generally want code to be able to run in multiple URL contexts (i.e. code should work when executed from different parts of the site). We can't use relative URLs starting with "/" because the site may not necessarily be installed on the root of a domain name.
- We don't want to hard-code domain names into URLs either, so can't use plain absolute URLs. We need our code to run on development and test installs.
- We need things to go through the configuration layer, e.g. showing the correct theme image for the theme a user has active, or handling configured Composr page redirects
- For page URLs we inject keep_* parameters into the URL query string, as those are designed to propagate between Composr URL requests (i.e. stay in the address bar as you browse the site)
For this reason we always build up page URLs using the build_url function. It essentially takes a map of parameters, and the zone the page is in.
For theme images, we use find_theme_image.
For entry-point scripts we use find_script to locate the script.
For other URLs we typically will prepend get_base_url() . '/' to turn a relative URL into an absolute URL. Or in templates, prepend {$BASE_URL*}/.
URL monikers
URL monikers (use of title-derived phrases in URLs, rather than numeric IDs), work transparently behind the scenes.Within Composr you generate URLs to the IDs, but Composr then converts those into the monikers, and back from the monikers, within the system architecture.
To support URL monikers you need to define a new content type, via defining a new content_meta_aware hook for it.
You need to define all the details in the hook, which is frankly a complex task. Some of these will be defined as null, as you probably won't (for example) have a search hook to tie it into.
The specific ones relating to URL monikers are…
Code (PHP)
'support_url_monikers' => true, // Set to true
'connection' => $GLOBALS['SITE_DB'], // Database the resource table is in
'table' => 'example', // The resource table
'id_field' => 'id', // The field containing the ID number (what is used in URLs conventionally)
'title_field' => 'title', // The field containing the resource title (what the moniker will generate from)
'title_field_dereference' => true, // Whether the title_field is a language string field; if you are not using content translation it doesn't really matter
'view_page_link_pattern' => '_SEARCH:downloads:entry:_WILD', // The URL pattern we support the monikers on
'connection' => $GLOBALS['SITE_DB'], // Database the resource table is in
'table' => 'example', // The resource table
'id_field' => 'id', // The field containing the ID number (what is used in URLs conventionally)
'title_field' => 'title', // The field containing the resource title (what the moniker will generate from)
'title_field_dereference' => true, // Whether the title_field is a language string field; if you are not using content translation it doesn't really matter
'view_page_link_pattern' => '_SEARCH:downloads:entry:_WILD', // The URL pattern we support the monikers on
Breadcrumbs
If you are making a new module you are likely to want to implement breadcrumbs.Let's say you have a front page to the module, and you have something in a category with a parent category "Bar" and that has a parent category "Foo" and that has a parent category "Root".
This would create: Module index > Root > Foo > Bar
_SELF:_SELF means "current zone, current page". It stops you having to hard-code zone and page names.
Composr automatically puts stuff in front, and puts the title of the current page on the end (as a non-link), so it would show something like: Home > Module index > Root > Foo > Bar > Something
Of course, in real code you are more likely to put this together in a loop, so your code will be more like:
Code (PHP)
$breadcrumbs = array();
$_category_id = $category_id;
do // Recursively find parents and put each as a breadcrumb
{
list($_category_id, $_category_name) = find_parent($_category_id);
if ($_category_id !== null)
{
$breadcrumbs[] = array('_SELF:_SELF:category:' . strval($_category_id), $_category_name);
}
}
while ($_category_id !== null);
$breadcrumbs[] = array('_SELF:_SELF:browse', 'Module index');
breadcrumb_set_parents(array_reverse($breadcrumbs));
$_category_id = $category_id;
do // Recursively find parents and put each as a breadcrumb
{
list($_category_id, $_category_name) = find_parent($_category_id);
if ($_category_id !== null)
{
$breadcrumbs[] = array('_SELF:_SELF:category:' . strval($_category_id), $_category_name);
}
}
while ($_category_id !== null);
$breadcrumbs[] = array('_SELF:_SELF:browse', 'Module index');
breadcrumb_set_parents(array_reverse($breadcrumbs));
The above code is just illustrative. The find_parent function is not real, nor is $category_id – substitute as appropriate for whatever you write/use yourself.
If the title of the current page is too long or looks weird in the breadcrumbs, you can override it
Code (PHP)
breadcrumb_set_self('Thing');
Redirects
It is quite common to want to automatically redirect from one screen to another.For example, after an action is performed, you may want to redirect from the screen actualising the action, to somewhere else.
You can do this by returning a redirect_screen. It goes something like this:
Code (PHP)
$url = build_url(array('page' => 'somepage'), 'somezone');
return redirect_screen($this->title, $url, do_lang_tempcode('SUCCESS'));
return redirect_screen($this->title, $url, do_lang_tempcode('SUCCESS'));
redirect_screen handles a few things for you:
- It sends a full redirecting screen to the user's browser, saying a redirect is happening
- It redirects using both HTTP header and meta tag, for maximum reliability (some server environments don't support HTTP header redirects)
- If you are viewing a "special page mode", such as the query list, the redirect is suppressed
- It attaches a message explaining the redirect has happened (the SUCCESS language string in the above example); this message is shown after the redirect has happened
- It also propagates any attach_message calls onto the final screen, so that any messages put out will actually be seen
If you just want to do a simple redirect without returning a screen, you can use assign_refresh:
Code (PHP)
require_code('site2');
assign_refresh($url, 0.0);
assign_refresh($url, 0.0);
Of course you can also just do raw PHP, for the simplest cases:
Code (PHP)
Database structure
We describe Composr's database structure in a separate document.This document includes a data-dictionary, and links to ERD diagrams for different parts of Composr.
Diff tools
WinMerge

(Click to enlarge)
- Seeing what code you might have changed (e.g. if you made a quick bug fix and need to send through a bug report saying what to change).
- Seeing what code someone else might have changed (e.g. between Composr versions, if you've found there's a new bug and want to see what caused it).
- If multiple developers conflict, you can sync changes.
- Updating overridden lang files with typo-fixes from the main Composr.
- A whole lot more!
Member profile customisation
Storing extra member fields
Custom profile fields allow webmasters to add new fields to member records, extending the system. This ability is often needed by programmers too, if their functionality requires extra data to be stored for individual members. It is ideal for this to be done using custom profile fields, edited on the same edit-profile screen as their existing fields. However, it is not possible to predict what the ID numbers of custom profile fields will be (necessary for recall), so Composr provides a special mechanism for programmers that allows definition and recall of customer profile fields, under identifiers of their choosing.To do this:
- Add a custom profile field in your module's installation code, via a regular install_create_custom_field function call on the forum driver. This is a special function created purely for the purpose of creating system member profile fields. It works on any forum driver, not just Conversr – for Conversr it sets Conversr custom profile fields, and on most forum drivers it also sets custom profile fields, but on a few it might just alter the database structure directly.
- Pass in the name of the custom profile field as <your-chosen-name> (e.g. example). It will be stored with an cms_ prefix, which indicates it is a system field.
- Conversr-only. Define a language string SPECIAL_CPF__cms_<your-chosen-name> that contains the true human-readable name. You can define this in your own language file.
- Conversr-only. Write a new systems/cns_cpf_filter hook. If you want your field to be editable, you need to include it as a key in the returned array of the to_enable function (see existing hooks for examples). You can use one hook file for lots of fields. Your function should require_lang the language file you defined your strings in.
Conversr stores the data in two tables (you should not need to know this, but it may be useful if you are manually checking the database during the debugging process):
- f_custom_fields – this stores the field definitions, one field definition per row. Think of it being like a schema.
- f_member_custom_fields – this stores the actual field values, each row represents a member and the field values are spread across normal database columns (aka fields).
Showing new links on member profiles
To add new links to member profiles, write a modules/members hook. Look at existing hooks as examples.Running extra startup code
To run extra startup code write a systems/startup hook. You can set it up to execute at a number of points in the bootstrapping process.Adding to the Admin Zone/CMS menus
To do this write a systems/page_groupings hook. Look at existing hooks as examples.Adding a new symbol, to refer to custom data and functions within templates
To add a new symbol you'll need to write a systems/symbols hook. This is a very useful technique for extending the Tempcode system.Running scheduled scripts
To run a scheduled script you'll need to do it via writing a systems/cron hook. For it to work, CRON must be set up on the server and tied into Composr (described in the Composr documentation). Look at existing hooks as examples. Alternatively, if you do not want to bother setting up CRON, or want to see the script output (e.g. errors) when debugging, just call up http://yourbaseurl/data/cron_bridge.php manually in the browser.Running temporary code
If there's some code you want to run once (e.g. if you are running a test, or running a quick bit of code to fix some data) you may find our data_custom/execute_temp.php useful.The advantages to this file are…
- It automatically loads up extra code useful for doing common structural changes (e.g. menu changes, module management). In other words you don't have to call up so much code yourself.
- It is configured to output plain text (text/plain mime-type), so you don't have to template any debug output you put out. If you see if output something other than plain text then that's probably because your code generated an error, which will cause a text/html mime-type.
- It exists for no other purpose than running temporary code. You won't break anything by putting your code in there.
Just write your code into the execute_temp function, load up the file by URL, and the code will run. Then delete your code when you're done (actually that's optional, unless the code is dangerous in some way and should never be run again by a hacker – so you can keep the code around a bit if you want to use it again later).
Tip
How Tempcode works
The Tempcode object structure
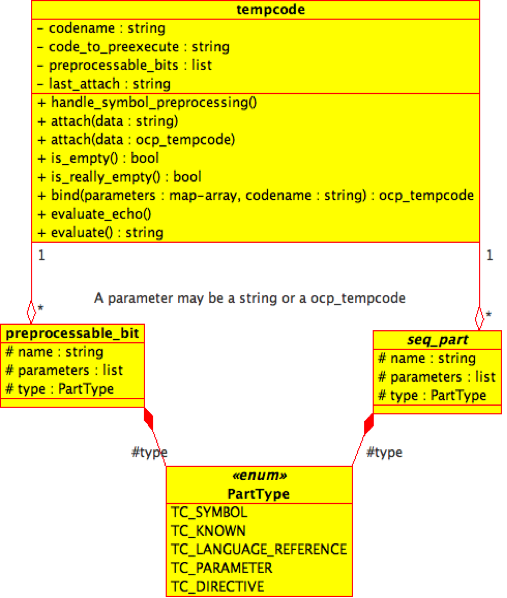
(Click to enlarge)
It has to achieve a number of key design goals (these are implemented in Composr's Tempcode engine – you don't need to worry about them, and that's part of the magic of Tempcode – for documentation see the Composr Tempcode programming tutorial):
- It has to be able to cache
- When cached it must remain 'smart' – it cannot cache statically, as things will be in cached Tempcode that need to change over time (for example the GLOBAL template might show the current server date and time – caching must be smart so that when it comes out of the cache it still shows the correct date and time)
- It must not use too much memory
- It has to be very very fast
- It has to be simple for a programmer to use (via the PHP API)
- It has to be simple for a themer to use (via the written language)
- The template structure must be preservable, so themers can see what structures different screens use
- The full Tempcode language has to be supported, with loop's, if tests, escaping, etc
- It must be preprocessable. For example:
- a template might include a block, which might require some CSS – this CSS would need to be included in the HTML <head> before the block itself was output
- the SET/GET feature has to work, even if SETing something that an earlier template GETs
Tempcode works via a very elaborate concept that we call the 'closure tree'. Essentially Tempcode objects link to form a tree structure via parameters. If you pass some Tempcode to a template as a parameter, that parameter is encoded into the Tempcode tree of the result of the template call.
Each Tempcode object consists of a series of 'closures' (stored as a seq_part). These closures are a pair: a PHP function name, and a set of parameters to that function. Essentially each closure represents a template call – the PHP function name is the name of a compiled version of that template (templates are compiled to PHP code), and the parameters are the parameters to the template. A Tempcode object represents more than one template call because Tempcode gets attached together using the attach method. This is why we say seq – as in, the sequence of attachments stored inside a particular Tempcode object.
Some complex tracking goes on to ensure that the correct template functions are defined or loaded, as required by the closure tree. Some of these functions are actually encoded directly within the Tempcode objects via code_to_preexecute (ones that were defined at run-time, such as attached string literals), and some are defined in the ".tcp" files.
Even more detail (you probably will want to skip this)
When I say "function call" and "function", this is actually simulated for performance reasons (PHP uses huge amounts of memory to store real functions). It actually happens via an eval call. There are a few exceptions to this where real calls are used, when a template is so commonly used that we think it does justify getting loaded up as a real function.Tempcode in ocPortal 3 worked in an entirely different way to ocPortal 4+. It was actually an interpreted programming language, and hence was quite a lot slower (while PHP of course is an interpreted language itself, it is fast because it is interpreted by assembly code). Rather than being compiled PHP, it essentially used the equivalent of op-codes and operands. Tempcode in ocPortal 2 was similar to ocPortal 3, except a bit more primitive – ocPortal 3 would 'flatten' the template tree, and was very clever about being able to merge certain things to increase execution speed and memory consumption.
I have just explained the history of Tempcode so I can make an important point – Tempcode is a bit of a black-box, and the internal engine can be rewritten so long as the API, written language, and semantics, are preserved. If the Tempcode language is ever changed, the caches need to be cleared – to clear away any compiled Tempcode (we never store anything primarily in compiled Tempcode – instead we store in Comcode and cache the Tempcode).
Development mode

- You will get error messages if you use too many queries, unless $GLOBALS['NO_QUERY_LIMIT'] is set to true.
- Cookies will be disabled, forcing use of keep_session for session propagating. This helps us make sure Composr doesn't need cookies to run.
- Persistent caching will randomly toggle between on and off (this can cause strange XML errors occasionally due to a race condition in the text-based persistent cache – try refreshing the page if you get random XML errors).
- If you create a bad link to a screen (e.g. without using build_url) you will get an error about that. This is because keep_devtest=1 is passed through and must be passed through for any referred (i.e. internal) link. Don't manually pass this – the code must do it itself, as it is injected by build_url to prove build_url was used.
- Form field descriptions will be forced to end with full stops (.). We want to encourage consistent use of English grammar.
- The template cache will randomly get emptied.
- Extra error messages if you try and pass a number to do_lang or do_lang_tempcode (you are supposed to convert to a string first manually).
- You'll get an error if you don't call a template ending _SCREEN at some point during your code. This enforces our convention of labelling for the screen templates.
- Relative URLs will intentionally not work, due to an intentionally broken HTML base tag. This forces you to use absolute URLs as per coding standards. One exception is URLs like #example, which are broken by the base tag, but then fixed at run time using JavaScript – you are allowed to use those.
- To save time you can define language strings inline in PHP code, and then Composr will automatically find the closest matching loaded language file to the name of the page you are running, and then move your inline definition into that file while removing it from your PHP file. For example, you can write: do_lang('EXAMPLE=This is an example'); and as soon as it runs for the first time the definition will be shifted into a proper language file. Note that if the call does not get executed, nothing is done – but that's a good way to see if you're not testing your code fully.
You can turn off most of development mode by putting "&keep_no_dev_mode=1" into the URL, but this is not promoted as development mode was intentionally written to help us do on-the-fly testing of things that might otherwise go unnoticed.
Custom version of PHP
Our custom version of PHP (linked to under "Programming/programmatic-interface standards") performs 2 main functions:- It makes PHP type strict (if turned on, which Composr does do), so that automatic type conversion results in a PHP notice, which causes a Composr stack dump.
- It turns on some very special innovative XSS security hole detection code. All PHP strings are tagged as "escaped or non-escaped", and this tagging is maintained through all string operations (e.g. if a string that is escaped is appended to a string that is non-escaped, the result will be a string that is non-escaped). Functions like htmlentities result in escaping being marked, and there is also an cms_mark_as_escaped function to force this manually (useful if you are intentionally injecting HTML literal code, e.g. from an RSS feed). If you output a non-escaped string, a PHP warning is produced about it – because the developer has not blocked what could well be an XSS security hole. We're very proud of this system, and how elegant it is, and as far as we know it's not anything anyone has done before – it took quite a few thought experiment sessions until we can up with it.
It also enforces some other coding standards, such as not allowing relative paths to files.
Importers
Import or forum driver?
Forum/member integration, done using a forum driver, allows Composr to integrate with an existing forum/member system in a number of ways. One of the biggest is so that you don't need to separately log in to both systems. Composr also uses the forum's members and usergroups, and stores/reads posts from the forum. Forum/member integration is achieved via forum drivers.Composr always uses one forum driver. The user picks a forum driver when the install and the default is the 'Conversr' driver which actually allows Composr to use its own inbuilt forum (Conversr).
Generally ocProduct's advises people not to use forum/member integration, but rather to use the inbuilt Conversr forum instead (and therefore the 'Conversr' driver). This is because it's much cleaner just to have one piece of software. This said, people often have valid reasons for avoiding a migration.
If one wishes to use Conversr but currently uses a different forum/member-system, then importing is the answer. If one doesn't care about Conversr but currently uses a different forum/member-system, then a forum driver is the answer.
Sometimes you want the advantages of migration, but don't want to move too quickly. ocProduct's approach to supporting these kinds of migrations is to provide forum drivers, but also importers, so people can choose to move to Composr slowly in two separate steps:
- install Composr using a forum driver
- import the forum into Conversr and discard old forum).
Forum drivers and multi-site-networks
When you need Composr to read forum/member information from the database, you should use $GLOBALS['FORUM_DB'] instead of $GLOBALS['SITE_DB'].This is for two reasons:
- because the third-party forum (if there is one) may not be in the same database as the rest of the site, or at least may not have the same table prefix.
- because you may be using a multi-site-network, i.e. a forum/member system shared between multiple Composr installs – and thus you need to draw from the central database.
If neither of the above reasons apply then it won't make any difference which you use, but you should do it correctly so that the above cases work properly on websites that do use these features.
As a general rule, if a Composr table is stored in a table starting f_, then it is a part of the inbuilt forum (Conversr) and should be accessed via FORUM_DB. You should also consider whether you should be accessing it directly, as opposed to using the forum driver interface – as any code you write will be assuming Conversr is being used.
In the case of Conversr, the forum driver just ties into the lower-level Conversr API. In the case of others, it's a basic clean-room implementation of accessing the relevant forum software's DB and files.
Stuff that is not an Conversr feature but uses the forum, has to go through the official forum driver interface. We can supplement functionality exclusively targeted for Conversr with a if (get_forum_type() == 'cns') guard. If we are coding functionality that is directly a part of Conversr (i.e. accessed in some Conversr-only part of the system, like the forum zone), then we don't need to worry about any of this.
Writing a forum driver
A forum driver works via a sources/forum/*.php file. A forum driver is basically an implementation to a standardised interface, and is accessed from ocPortal via $GLOBALS['FORUM_DRIVER']. There's not a lot to say about this, as there are so many existing forum drivers in Composr to look-at/refer-to and they all follow a pattern. The API is mature and simple.To make a new forum driver just copy an existing one and give it a new filename corresponding to the software being imported. To use the driver the _config.php file will need to reference the stub of the filename you chose in its forum_type option. You shouldn't switch forum drivers on a real Composr site because it breaks foreign key references in Composr tables (member IDs are group IDs) – but you can do it when developing. It's probably best to install Composr using Conversr, write your new forum driver and switch to it while you debug it – then install again from scratch using your new forum driver from the offset.
Writing an importer
The import system (the admin_import module) provides a framework for importing data into Composr from other systems. The system provides both a GUI and an import API.An importer imports data from the database of some other software into Composr. So it takes database records and converts them. The end result is the data is then part of a Composr-powered website.
To learn how to write an importer consider copying an existing one (preferably one written for a product similar to the product you are importing) and adapting it. Work through the code function by function, adjusting field names and other code as appropriate.
Always test a new importer and keep backups before actually running it on your data. It is surprisingly easy to make a typo in an update query, for example, which will trash a whole table (and if also accidentally executed on the source database, perhaps more disastrous).
Implementation structure
Importers are implemented using the Composr 'hook' system, meaning that a new importer may be added by just copying the importer-file into the sources_custom/hooks/modules/admin_import directory. At the time of writing, the following importers are available:- phpNuke 6.5 (with possibly other versions and forked-products partially compatible)
- phpBB 2
- vBulletin 3
- Invision Board 1.3.x
- Invision Board 2.0.x
- Merge from another copy of the latest version of Composr
The importer-file consists of an object that defines:
- a probe_db_access function that tries to auto-detect database connection details from the given installation directory of the software being imported
- an info function that provides importer details through a standard data structure. These details include:
- the name and versions of the product(s) the importer supports
- the default table prefix for the database of the product
- a list of all the available importable features in the importer, roughly ordered in the order they should be imported in (all of which have feature_<codename> associated functions in the importer)
- a feature dependency map (to prevent users importing in the wrong order – which they may do as they are allowed to skip features so long as there is no defined dependency by what they import next)
- a message to display after the import has completed. In the case of most of the existing importers it's a standard message telling the user to go run our cleanup tools.
- miscellaneous other advanced details
- feature-import functions, which are named according to the code-names of the import features listed within the info data structure (import_<feature>). The object only needs to define feature-import functions for those features it can import.
- any other miscellaneous functions that the importer may use internally (sometimes importers have their own unique situations where moderately complex conversion of data between representation schemes is required, and support functions are often useful to keep the code tidy)
If you need to import a feature for which no import code exists yet then you'll need to define it. They are defined by hook files in sources/hooks/modules/admin_import_types. Each hook file has a function that returns a mapping between import codes and the language string identifiers that label them. e.g. the 'filedump' code is defined in sources/hooks/modules/admin_import_types/filedump.php and is set to be labelled to the user with the language string 'FILEDUMP'. If you need to create a new import code put it in the most appropriate hook file that already exists (probably cns_forum.php). Try and re-use an existing language string if one exists, otherwise create one in lang/EN/import.ini.
Flow
The import system mainly provides a workflow via its GUI, and the actual API is relatively light-weight (although the whole Composr API is available to importers). The workflow is as follows:- Finds which importer to use (options available correspond to what hooks are on the file system)
- Finds an import session to continue, or starts a new session (described below)
- Gets path details for the system being imported
- Verifies the path details and auto-probes for database connection details
- Provides the user a UI for working through each importable feature, one-at-a-time
The importer system uses a concept of 'import sessions'. These are built on top of the Composr login sessions, and are an important feature in allowing you to merge multiple sites into Composr: they keep the progress and "ID remap table" from each import separate. The "choose your session" interface exists so that if your Composr session is lost, you can still resume a previous import.
The importer system is designed to be robust, and is programmed as 're-entrant' code; this means that if installation is halted, via failure, timeout, or cancellation, it can continue from where it left off. This is of particular use if there is an incompatibility between your data and the importer, which is not very unlikely due to the wide variation in data for any single product across different versions and usage patterns.
Coding techniques and notes
Often special Composr API parameters are used to disable cache-regeneration and input-sanitisation-checks, to allow for a smoother and more error-free import. For example, if you're adding a topic in an importer you don't want to check poster permissions, so the cns_add_topic function has parameters to disable its internal-checks.The import API gives importers an ability to do foreign key conversions. For example, when importing a topic an importer will likely need to convert the foreign key representing who posted that topic into whatever it has been imported to (a member ID#5 on the import data may now be member ID#9 on Composr). This API is very simple: you just set key remappings when they become known (when importing the feature being referenced), and then look them up when importing whatever uses the key. You can treat the foreign keys either as a dependency (giving an error if there is an inconsistency in the data being imported) or you can handle failed lookups whatever way you wish.
One problem with importers that import members is that almost always passwords are not available and not compatible with Composr's hashing scheme. To workaround this:
- Conversr needs to be given a handler for the password hashing scheme. This is done by writing a special systems/cns_auth hook.
- The member must be imported with a reference code representing the hashing scheme to use (the cns_make_member function supports passing this in)
A common mistake when writing importers is with HTML entities. Some software stores some fields as HTML (albeit taglessly – just with the entities), while Composr never does. You need to decode any HTML fields using html_entity_decode before passing them into the Composr API, like "html_entity_decode($field_value,ENT_QUOTES,get_charset())".
If you are unsure how software stores its data, enter test data that uses various quotation mark symbols, so that it will jump out at you when you view the raw database.
There is a very complex situation for non-forum importers that use forum-driver functions during import, in order to find data to associate with database records they are creating. For example, an importer for a simple download system which stores 'usernames' of download-submitters, might wish to try to bind these usernames to actual user-IDs, using the forum-database that Composr normally uses. However, by default the forum-database is tied to the local-Conversr-install during installation, as when forum data is imported, this Conversr database is required (as this is where the information will be piped to). Therefore there are two import API functions that allow switching to and from local and M.S.N. Conversr installations:
- cns_over_local (this sets Composr to use the local Conversr for the FORUM_DB object)
- cns_over_msn (this sets Composr to use the database of the regular forum for the FORUM_DB object – which may or may not be Conversr, and even if it is Conversr, it might not be the local Conversr)
A related problem is that some parts of Composr's API might assume that the FORUM_DB object points to Conversr if the get_forum_type function returns cns; or there can be problems with reference variables that confuses forum driver objects. Therefore running these commands might be required in some other cases – in particular when Comcode is being parsed. Don't worry too much – emulate what the other importers do.
Sometimes data in software being imported has no use in Composr, or isn't quite compatible with how Composr does things. When the developers make an importer we try to make a call in these situations as to how important the feature is:
- almost always it is fairly trivial (e.g. an option that does not exist in Composr as we'd use a template edit instead). In this case we would ignore the option.
- sometimes a bit of clever code can convert the data into something useful.
- if it is something that seems important, either a feature would need adding to Composr, or whoever has commissioned the importer would be consulted, or the issue would be documented. It shouldn't be ignored completely.
eCommerce

For reference, the described eCommerce hooks have the following methods:
- product_info
This is a custom function for hooks to report their products' information. It is an array, where each entry has a key that is the product codename and a value that is an array that gives the attributes of one product (the product type, the price, the name of the custom function, an array of product-type-specific details which is often empty, and the product title). See other hooks for examples. You need to implement this for the hook to be usable in any way. Once implemented you will be able to use the Composr purchase module to see your hook's products, and select them for purchase.
Valid product types are:- PRODUCT_PURCHASE_WIZARD (a one-off purchase)
- PRODUCT_INVOICE (an invoice payment) – you are very unlikely to need this one
- PRODUCT_SUBSCRIPTION (a subscription payment – the product details array should contain length and length_units values to define how the subscription will work). length_units can be d, w, m or y. An example product details array (this would be for a subscription that recurred every 1 month): array('length' => 1, 'length_units' => 'm')
- PRODUCT_OTHER (something that is not purchased via the purchase wizard, but done manually – usually it is something the website staff are adding manually to show up on the eCommerce charts, not something actually related to the website itself) – you are very unlikely to need this one
- PRODUCT_CATALOGUE (a shopping cart product) – you are very unlikely to need this one
- PRODUCT_ORDERS (a full shopping cart order) – you are very unlikely to need this one
- get_needed_fields – This function will return field Tempcode, for inclusion in a purchase form.
- set_needed_fields – This function processes the data entered from the purchase form (get_needed_fields), or if there was no purchase form it may act on URL parameters that might be present. Often this function is used to save data into the database prior to purchase (after purchase the data would then be retrieved/processed/marked-active). You can assume this function always runs in a screen after get_needed_fields, and therefore you can use the normal functions like post_param_string to read in the data. This function returns the purchase-ID, which henceforth is used to refer to the sale (and thus, retrieve its data). The purchase-ID is often a database key, for the case of a row being added – but also often it instead is more implicit (e.g. a member ID, or a chosen codename).
- get_identifier_manual_field_inputter – This optional function (often not used) will return field Tempcode for allowing an administrator to select an identifier when manually triggering a purchase. Often identifiers are automatically worked out (in fact, often they are member IDs of the purchasers), so this method allows a more user-friendly open selection for the identifier for the case where the identifier likely is not auto-computable (i.e. when the administrator is purchasing on behalf of a third-party).
- get_agreement – This function will return licence text to be approved by the buyer. Some product do not need licence agreements and hence do not need this method.
- get_message – This function gets a message that will be displayed inside the purchase wizard. Often a very general description of the hook's products will be shown from here.
- is_available – This function returns the status of product: whether it is available or not. For example, often products are not available to Guests (because there is no member ID to save a purchase against), or a product may not be available due to it being out of stock.
- A user defined function – A user defined function to run while finishing an order transaction (it will be called automatically). It's name is that you added as an array element in the product details array returned from the get_products() function. Note this is a function, not a class method.
- get_product_dispatch_type – This optional function will return the dispatch type for a product. It will return manual or automatic – most products are automatic (they require no manual effort to be dispatched – the code sorts it out automatically).
- enable_manual_transaction – This optional function will return whether manual transactions (from the Admin Zone) are allowed or not. If enabled, uncompleted transaction's orders will display in Admin Zone->Usage->eCommerce >Manual transaction screen. Administrator can trigger the transaction as complete if he/she got an external payment via direct cash or cheque etc.
Forum drivers
Composr supports third-party forums. This is so people who have an existing/preferred forum and need a CMS for it, can still benefit from Composr. For example, comment topics for news are stored on the forum, even if it's a third-party forum.The user picks a forum driver when the install, which maps to a sources/forum/*.php file. A forum driver is basically an implementation to a standardised interface, and is accessed from Composr via $GLOBALS['FORUM_DRIVER'].
In the case of Conversr, the forum driver just ties into the lower-level Conversr API. In the case of others, it's a basic clean-room implementation of accessing the relevant forum software's DB and files.
Stuff that is not an Conversr feature but uses the forum, has to go through the official forum driver interface (unless you're working on an addon or a private site). We can supplement functionality exclusively targeted for Conversr with a if (get_forum_type()=='cns') guard. If we are coding functionality that is directly a part of Conversr (i.e. accessed in some Conversr-only part of the system, like the forum zone), then we don't need to worry about any of this.
Permissions
Permissions are drawn from usergroup membership. Usually a forum allows multiple usergroup memberships per member (the inbuilt Composr forum system, Conversr, does). This allows you to more effectively mix and match permissions for individual members and cuts down the total number of usergroups required.The permission architecture in Composr is particularly rich, giving the webmaster a high degree of control over their site, but where complexity is only added in if they need it. There are view permissions and privileges. Privileges can be overridden on a per-page and per-category basis, but otherwise apply globally from a simple list of settings.
Note
You need to be authorised a number of barriers (zone, page, category) before you are able to view a resource.
Permission-modules are simply string codes (e.g. downloads) used to specify what kind of resources (e.g. download categories) identifiers are referencing – in order to specify which view permissions or privileges are set. For view permissions it's simplest: permissions are set against a permission-module (e.g. download) and an identifier (e.g. '3') and looked up correspondingly.
The term 'module' here is not exactly the same as a 'module' in the usual Composr module-page sense. A permissions-module is usually given the same name as the page-module for viewing the resource it identifies permissions for, but it may not be if the page-module supports multiple types of resource. For example, the catalogues page-module has support for both catalogue-permissions and category-permissions, so the permission-modules are catalogues_catalogue and catalogues_category.
When global privileges are overridden for pages, the page that the overriding is defined for is usually the name of the content management page; for example, if the add_midrange_content privileges is overridden (this permission controls whether a member may submit a 'medium-impact entry', like a download or image) for the download system as a whole, it would be overridden with the page name cms_downloads.
If we were overriding for a category, it would then be the permission-module that identified the type of category we were overriding for, and the ID of that category would also be stored. E.g. if we were overriding for a download category '3' (permissions module is downloads), we'd be referencing 3 and downloads.
Note the distinction between overriding for a page, and for overriding for a permission-module – for many permissions webmasters can override for both, meaning page names and also permission-modules/identifiers together need to be passed to the API functions. If the Permissions Tree Editor allows an override to be set, you must make your permission calls respect this by referencing the correct permission-modules and page names. It is the get_privilege_overrides function of a module (e.g. cms_downloads) that defines what permissions may be overridden.
Privileges are checked and set purely through the permissions API (has_privilege), using permission-modules (e.g. downloads) and identifiers (e.g. '3'). There are no hooks needed, just:
- the name of the privilege
- the name of the page that controls its overridden value (if there is one, e.g. cms_downloads)
- the combination of permission-module and identifier (if it can be overridden per-category)
View permissions are checked using the has_category_access function, or other similar functions if zone or page view permissions are being checked.
(A final point of note is that of SEO-modules and feedback-modules: these define yet another set of 'module' names: these are however totally unrelated to permissions.)
Referencing existing permissions
It is very easy to reference existing permissions from your code. Just use the has_privilege, has_actual_page_access, and has_category_access functions. Note that it is important to use the has_actual_page_access function if you're accessing resources belonging to a page-module if you aren't running at page-module code itself at the time (e.g. the RSS feed for the page-module). You actually don't need to call has_actual_page_access from page-module code itself because Composr checks this for you.The has_privilege function supports checking full overrides as well as just basic global settings. To do full override checks you can give parameters to specify what page-module you consider your resources to belong to, as well as permission-module and category IDs.
If you are going to do override checks though, make sure that your page-modules define what they can override so that the Composr Permissions tree editor knows what to make editable. For examples of how to do this, see cms/pages/modules/cms_downloads.php and site/pages/modules/downloads.php.
Adding a new privilege
In the install function for your page-module, add the following code to actually add the permission:Code (PHP)
add_privilege('FOO_SECTION', 'may_foobar', false);
In the uninstall function for your page-module, add the following code:
Code (PHP)
delete_privilege('may_foobar');
Code (INI)
PRIVILEGE_may_foobar=May foobar
SEO metadata
To allow SEO (search engine optimization) metadata in your addon, the following is roughly required for different sections of the addon's page-module code. This example is for the download system:This function seo_meta_set_for_implicit() implicitly (by virtue of extracting keywords from the strings it is passed) sets the meta information for the specified resource. Add it in the model add_download function:
Code (PHP)
In the CRUD CMS-module, you need extra parameters to the call to the model edit_download function:
Code (PHP)
,post_param_string('meta_keywords'), post_param_string('meta_description')
In the model edit_download function you need to take the extra parameters:
Code (PHP)
, $meta_keywords, $meta_description
Code (PHP)
The function seo_meta_erase_storage erases a seo entry… as these shouldn't be left hanging around once content is deleted. Add this function in the model delete_download function, you need to clean up:
Code (PHP)
seo_meta_erase_storage('downloads_download', $id);
In the page-module you need to load up the settings when the content is viewed:
Code (PHP)
Feedback mechanisms
Composr allows webmasters to create a highly interactive site, with numerous features for user feedback at disposal. You are able to add ratings, comments, trackbacks, and staff notes to a module.We recognise that many websites owners will not wish to allow users to affect the state of their website: because of this, commenting and rating may be enabled/disabled on a site-wide basis. They are, however, enabled by default. To disable the elements of the feedback, check-boxes are given in the 'User interaction' subsection of the 'Feature options' section of the main Admin Zone configuration page.
In addition to site-wide control of feedback, it may also be enabled/disabled on a content entry level. For a piece of content to support rating, for example, that content must be configured for rating, and Composr must have rating enabled site-wide.
Feedback commenting is very similar to, and actually implemented as, a forum topic being attached to a piece of content, and displayed beneath it. To allow users to comment on Composr content, in addition to site-wide commenting any commenting for the content entry being enabled, the named comment forum must exist; the default comment forum name is 'Composr comment topics', but this is configurable in the main Admin Zone configuration page.
Add the following code snippets to enable your feedback system (roughly, this code is liable to go out of date a bit as we evolve the system)…
In the install function for your module, in the table creation…
Code (PHP)
'allow_rating' => 'BINARY',
'allow_comments' => 'SHORT_INTEGER',
'allow_trackbacks' => 'BINARY',
'notes' => 'LONG_TEXT',
'allow_comments' => 'SHORT_INTEGER',
'allow_trackbacks' => 'BINARY',
'notes' => 'LONG_TEXT',
In the uninstall function for your module…
In the run function for your module…
Code (PHP)
require_code('feedback');
In the get_form_fields function header of your CRUD CMS module…
Code (PHP)
, $allow_rating = 1, $allow_comments = 1, $allow_trackbacks = 1, $notes = ''
In the get_form_fields function of your CRUD CMS module…
Code (PHP)
$fields->attach(feedback_fields($allow_rating, $allow_comments, $allow_trackbacks, $notes));
In the add_actualisation and edit_actualisation functions of your CRUD CMS module…
Code (PHP)
$allow_rating = post_param_integer('allow_rating', 0);
$allow_comments = post_param_integer('allow_comments', 0);
$allow_trackbacks = post_param_integer('allow_trackbacks', 0);
$notes = post_param_string('notes');
$allow_comments = post_param_integer('allow_comments', 0);
$allow_trackbacks = post_param_integer('allow_trackbacks', 0);
$notes = post_param_string('notes');
In the fill_in_edit_form function of your CRUD CMS module, where the get_form_fields function is called…
Code (PHP)
, $myrow['allow_rating'], $myrow['allow_comments'], $myrow['allow_trackbacks'], $myrow['notes']
In the model add/edit actualisation functions add some extra parameters…
Code (PHP)
, $allow_rating, $allow_comments, $allow_trackbacks, $notes
In the model add/edit actualisation function query_insert/query_update calls…
Code (PHP)
'allow_rating' => $allow_rating,
'allow_comments' => $allow_comments,
'allow_trackbacks' => $allow_trackbacks,
'notes' => $notes,
'allow_comments' => $allow_comments,
'allow_trackbacks' => $allow_trackbacks,
'notes' => $notes,
In the model delete actualisation function…
In the view function for your content…
Code (PHP)
actualise_rating($myrow['allow_rating'], '<your_chosen_feedback_module_name>', $id);
actualise_post_comment($myrow['allow_comments'], '<your_chosen_feedback_module_name>', $id, $self_url, $self_title);
$rating_details = get_rating_box('<your_chosen_feedback_module_name>', $id);
$comment_details = get_comments('<your_chosen_feedback_module_name>', $myrow['allow_comments'] == 1, $id);
$trackback_details = get_trackbacks('<your_chosen_feedback_module_name>', strval($id), $myrow['allow_trackbacks'] == 1);
actualise_post_comment($myrow['allow_comments'], '<your_chosen_feedback_module_name>', $id, $self_url, $self_title);
$rating_details = get_rating_box('<your_chosen_feedback_module_name>', $id);
$comment_details = get_comments('<your_chosen_feedback_module_name>', $myrow['allow_comments'] == 1, $id);
$trackback_details = get_trackbacks('<your_chosen_feedback_module_name>', strval($id), $myrow['allow_trackbacks'] == 1);
In the main template call to display your content on its own screen…
Code (PHP)
'TRACKBACK_DETAILS' => $trackback_details,
'RATING_DETAILS' => $rating_details,
'COMMENTS_DETAILS' => $comment_details,
'RATING_DETAILS' => $rating_details,
'COMMENTS_DETAILS' => $comment_details,
CRUD modules
Most Composr create/edit/delete interfaces are done via an CRUD module, as this saves code and makes it easy to be consistent. CRUD modules get the following automatic functionality:- Add/edit forms
- 'Choose what to edit' forms
- Permission checking
- privileges for add/edit/delete
- ownership checks for edit/delete
- view permissions for edit (you can't edit what you can't view)
- unsetting of validation if the user can't bypass validation
- sending out new-content emails to staff
- Standard SEO fields
- Standard award fields
- Standard 'you should log in' messages
- Standard 'maximum file size' messages
- Standard 'please take care' messages
- Standard 'Do next' screens after performing an action
- Point awarding for content submissions
There are lots of CRUD module's to look at as examples in the CMS zone. This section describes how they work in general terms.
Each CRUD module extends the 'Standard_crud_module' base class. This class has many internal methods that abstract the interface and actualisation functions of the CRUD functionality, and it actually takes hold of the whole CRUD process, limiting the burden on us just to defining a few special methods/properties. We inherit from the CRUD class in our module to use its functionality. To do this it must first require up that class, just before the module is defined:
Code (PHP)
require_code('crud_module');
Rather than an CRUD module having a run method like most modules, they instead are given a 'run_start' method. This method is called automatically from the base class's own 'run' method, which handles screen types that are standard to all CRUD modules. The CRUD module defines the default screen type to be the 'add' screen type, unless you define a browse method within your own code.
CRUD module's define entry-points in a get_entry_point method like other module's do, however they also tie into the base class's function to return a compound result, as follows:
Code (PHP)
function get_entry_points($check_perms = true, $member_id = null, $support_crosslinks = true)
{
return array_merge(array('browse' => 'IOTDS'), parent::get_entry_points());
}
{
return array_merge(array('browse' => 'IOTDS'), parent::get_entry_points());
}
The standard entry-points defined by an CRUD module are:
- add, The UI to add a resource.
- _add, The actualiser to add a resource.
- edit, To choose a resource to edit/delete.
- _edit, The UI to edit/delete a resource.
- __edit, The actualiser to edit/delete a resource.
CRUD modules define the following standard methods:
- get_form_fields, To get form fields for the add/edit forms; this function takes parameters, but they must all be optional – the parameters will only be passed for an edit form (see below).
- fill_in_edit_form, To pass in existing field values to get_form_fields for an edit form; this function is passed the ID of the record being edited/deleted, which allows you to load up the data from the database in order to pass it through to get_form_fields.
- add_actualisation, To handle 'add' actions (usually ties into a model function).
- edit_actualisation, To handle 'edit' actions (usually ties into a model function); this function is passed the ID of the record being edited.
- delete_actualisation, To handle 'delete' actions (usually ties into a model function); this function is passed the ID of the record being deleted.
Often they also define the following:
- edit, If the auto-generated "choose what to edit" screen needs customising.
- create_selection_list_ajax_tree, If we are using tree list control in edit page, we need to define create_selection_list_ajax_tree function in our module. That tree list is using for selecting the editable data. We need to give the name of an systems/ajax_tree hook file which create the data for tree list to the Composr form_input_tree_list function. The hook file will return XML data for the tree list and the built-in Composr AJAX functions (called up by form_input_tree_list) will receive that data and fill it in tree list. In every node expansion in the tree list another AJAX request is generated to expand the particular node's ID. The AJAX script will find the child data for that parent ID and return its child data.
- get_submitter, If there is a complex calculation required for who submitted a resource (required for the purposes of permission checking).
- do_next_manager, If the standard do-next results screen is too basic (e.g. if extra icons are needed).
- browse, The function to show the screen when the module is loaded up. If we do not define this, browse acts the same as add. If you define a browse method (which many CRUD modules do do) then you must call it yourself from your run_start method. Often browse methods are used with do-next-manager interfaces, to provide a front end for choosing different options.
CRUD modules usually define the following standard properties:
- lang_type, the stem for languages strings the module would use. E.g. if you say 'FOO', the 'ADD_FOO', 'EDIT_FOO', and 'DELETE_FOO' language strings would all need to exist.
- archive_entry_point, an entry-point where a user can browse everything of the resource-type handled by the CRUD module.
- view_entry_point, an entry-point where a resource handled by the CRUD module can be viewed, with '_ID' in place of where the ID value would be.
- permissions_require, a value of either low, mid, or high – for the kind of permissions used for resources being edited.
- permission_module, the permission category code that identifies the module w.r.t. category access checks.
- permissions_cat_require (usually the same as permission_module).
- permissions_cat_name, the name of the field which holds the value that permissions are checked with respect to (usually the category field).
- array_key, the name of the ID field.
- orderer, the name of the field used to order results in the 'choose what to edit' list and also the title field.
- title_is_multi_lang, whether the title field (orderer above usually) needs to be dereferenced as a language code (i.e. it goes through the translate table, if multi-language content is enabled).
- table, the name of the database table used.
Often they also define the following:
- user_facing, whether regular users are likely to have access to the module (adds in extra user-friendly references that might seem a bit odd for a regular administrative module).
- send_validation_request, whether to send out e-mail notifications to staff when non-validated resources are submitted.
- upload, if set it should be image or file, and has the effect of extra 'maximum file size' messages being output, as well as other extra mechanism preparation.
- javascript, JavaScript code to be included when add/edit forms are shown; it is common to put code in here to handle field alternation (standard_alternate_fields), automatic field disabling based on values in other fields (e.g. not allowing specifying of the fine details to something if that something is not entered at all), or extra custom field value santisations.
- non_integer_id, whether the ID field for the table is a string (a 'codename' in Composr terminology).
Often the following are overridden at run-time, from the run_start method:
- add_text, a message shown on the add screen (usually set via do_lang_tempcode).
- edit_text, a message shown on the edit screen (usually set via do_lang_tempcode).
- cat_crud_module, a reference to a second CRUD module instance used for managing add/edit/delete of categories; CRUD modules can only add/edit/delete one resource set, but you can use this to pair up add/edit/delete of entries (the main module) to add/edit/delete of categories (the referenced one). Once you set cat_crud_module, the main module will automatically relay add_category/edit_category/_edit_category/__edit_category requests to the cat module, but continue to handle add/edit/_edit/__edit requests itself.
Attachment-supporting fields: Language lookup, Comcode, and attachments

- Define your tables correctly – human language should almost always be defined using a '*_TRANS' field type.
- To input Comcode data, use the Comcode versions of the field input functions (e.g. field_input_comcode). To allow new attachments to be added, you need to use a posting form.
- insert/update/delete your data using the correct Comcode/language/attachment functions. When used correctly, the special functions in Composr's API automatically handle Comcode parsing, and attachment uploading. For example, to add some Comcode, you use the insert_lang_comcode function as a filter to convert between Comcode-format string, to translate-table ID number (if multi-language content is enabled – otherwise it's a null-op) – and this ID number is then inserted using the normal query_insert function. See how the news addon code does it all for a better example – it is best understood by copying how existing addons do it.
- Retrieve your data using the get_translated_* functions.
- Attachment-support requires attachment hooks. These hooks work to grant users permissions to access attachments via their permission to access the resources that reference those attachments. For example, someone can access an attachment to a news article if they have access to that news article, or access to anything else that also references that attachment (such as a forum post).
Non-bundled addons
If you are working with the Composr git repository, you can commit addons into git without them having to be a part of Composr.Only do this if the addon would generally be useful to a decent number of people – things specific to one website, or one specific kind of website, should not be in the official git repository (unless it is a part of the Composr build/publish/website infrastructure).
To add the addon as non-bundled:
- Decide on the informal and formal names for your addon (e.g. "Fun time" and fun_time)
- Save files into *_custom directories wherever possible.
- Create a sources_custom/hooks/systems/addon_registry/<addon_name>.php file that lists all the files relating to your addon (including the addon_registry hook itself). Of course, all other settings in the addon_registry hook should be filled out.
- Put a screenshot in data_custom/addon_screenshots
- 'Add' the files to git, commit and push
Your addon can then be managed through the bugfix push system, and will be pushed when the addons are bulk-uploaded (done as a part of the new version release process).
Feedback
Please rate this tutorial:
 (
(
 )
)


Have a suggestion? Report an issue on the tracker.